 [/custom_frame_left] Did you receive a “new” article about robots.txt in the mail this morning? I did. As usual, it was the umpteenth re-hash of original content already available on the web, and written by yet another of the self-proclaimed experts who keep popping up like a bad penny nowadays.
[/custom_frame_left] Did you receive a “new” article about robots.txt in the mail this morning? I did. As usual, it was the umpteenth re-hash of original content already available on the web, and written by yet another of the self-proclaimed experts who keep popping up like a bad penny nowadays.
If so many publications about robots.txt are re-mixes or just plain copying of existing content, you need to ask yourself:
– What do we actually know about the robots.txt file and its importance?
– Why is there no fresh and up-to-date information about it, only remixes?
– What’s all the noise about?
Thanks to Martijn Koster, robots.txt has been around since 1996 and his site, The Web Robots Pages, is universally acknowledged as the reference of choice for advice about it.
What is it?
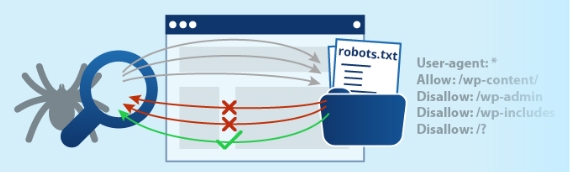
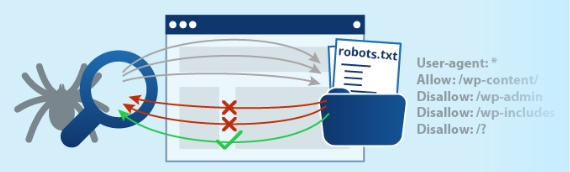
Robots.txt is truly an orphan file – it doesn’t even appear on your site map.
It’s never linked to any site pages, is more or less invisible for visitors, is always parked in the root file, after the slash, and it’s only of interest to spiders. Nobody else.
We’re told that robots.txt is a “good thing to have”, that it’s a useful guide for robot crawl permissions on your site, and Google recommends its use too – the ultimate accolade!
All the re-hash articles concentrate on telling us how to build the file.
Some authors even claim that it can be used to stop “bad bots” crawling your site – which is rubbish.
A “bad robot” will never check whether you have the file in the first place, let alone read and obey its commands. There’s even a site selling a generator for your robots.txt file for a princely $ 99.50 – daylight robbery! And they include advice as to how to use it to disguise your black hat SEO tricks, as if that’ll help you.
How Many Sites Actually Use it?
It is almost impossible to establish how many sites use robots.txt – in spite of all the publicity, there’s precious little evidence available on the web as to its usage.
A robots.txt file usage study (.doc document!) completed in 2000 / 2001 found that a valid file was present on:
– 9.8% of 1,195,359 ODP-listed web sites tested.
– 27% of the entire Alexa list of top 500 sites.
That’s not very many for “a good thing to have”.
Not much growth either when compared to their benchmark estimate of 5% to 6% for 1996.
What About Today’s Usage?
As the figures were very old – 2001 is way back in Internet time – I did a very limited usage test of my own by testing how many sites were using it in the webmaster forum I’m a member of.
I split the member list in two samples: 100 + posts and 40 / 99 posts, visited the respective member sites and checked for robots.txt availability.
Results:
100 + posts
404 – no file 50%
200 – ok 50%
40 / 99 posts (1 not live, 1 broke the back button!)
404 – no file 40%
200 – ok 60%
Conclusions:
A definite increase compared with 2001. You’d expect usage to be higher than average on a webmaster forum. 100 + posts members outperformed by the 40 / 99 post group – no time maybe? Or did members with 100 + posts know something the rest of us don’t?
When we’ve Got One, it’s Usually Invalid!
Some of the preliminary results of another use of robots.txt files study conducted in 2001 were:
– 50% in .doc format – invalid, as the correct extension is .txt.
– 60% ended up as redirects to an html page – many robots.txt files are valid, but stationed in an http redirect parking lot, often a custom-made 404 file – again, invalid, crawlers want .txt, nothing else.
– A further 6% of all other robots.txt files checked were also invalid.
A complete waste of time for the crawler, and your bandwidth and effort!
Should we Care?
If, like myself, you’re trying to earn a living off your domain without the money available to top 500 sites, the answer has to be: “I’m not really interested in knowing whether it’s being used or not.”
The important questions we want answered are:
– Will it help my site / be good for business – commercial importance?
– Does the competition use it / why – are they scoring better as a result?
– Will it improve my Search Engine Results Pages – SERP’s?
– A Google recommendation – why?
Is the robots.txt file commercially important?
To get an idea of it’s possible importance for our business, I conducted searches on google.co.uk, msn.com and yahoo.com for the single word that describes our industry (fitness), visited all page 1 results and called the robots.txt file.
These are the top 10 results for each search:
Google
404 (No File) – 50%
200 (OK) – 50%
MSN
404 (No File) – 80%
200 (OK) – 20%
Yahoo
404 (No File) – 50%
200 (OK) – 50%
Conclusions for our Industry:
I’d always assumed that any site worth it’s ranking in the SERP’s would have a robots.txt file on the site – forget it, it just isn’t so!
Its absence clearly doesn’t affect Google or Yahoo top 10 results and might even be an advantage on MSN!
I wonder how many of the MSN top ten also figured in the .doc error measured in 2001? Both MSN and .doc come from the same company and there are a lot of sites out there originally written in .doc code.
Search engines clearly couldn’t care less – they are in business to serve relevant results for human searchers and missing robots.txt files have nothing to do with their job.
So it appears that the absence or presence of a robots.txt file on your site:
– Will not harm nor help your site or business.
– Won’t give you a competitive edge.
– And has no effect at all on your SERP’s.
So Why Does Google Recommend its Use?
I don’t know – but let’s think about this for a moment. Ask yourself a couple of questions:
When did you last go on a long journey, in unknown territory, and without a map and route plan?
On a road paved by more than 55″ target=”_blank”>http://www.archive.org/web/web.php]55 billion web pages?
In an environment – the web – so totally dependant on 3 search suppliers?
Where milliseconds used to view robots.txt once – the map, saves a bot milliseconds on every page crawled on your site?
And time saved per page, no matter how little, multiplied by so many billions, has to add up to a clear efficiency gain for total spider indexing time?
What if they decide to delay indexing sites that don’t help them retain their competitive edge in the future?
What if that’s one of the sandbox factors right now?
Final Conclusion
Time saved is profits earned in any business, let alone the search industry.
Build it – see it as a form of insurance with a one-off fee – 10 to 15 minutes of your time.
As you don’t need both robots.txt and the,andtags, you can get rid of them.
The benefits:
Save a few bytes on each page – like weight loss, every byte less is good.
Improves your content / code ratio (great tool available as well to test yours) – which is always good for SERP’s.
It won’t hurt your site and anything that helps make your site more efficiently crawl able “has to be a good thing”.






